UI 与声音设计(上)

UI,User Interface,字面上就包括两个方面:user用户,Interface界面。现在我们已经把UI看作是j 交互界面的代名词。看起来是件非常简单的事情,但无论在理论还是实践过程中,UI在视觉、听觉和体验设计上都是一件很难的事情。并且可能也是产品设计最重要的一部分,用户从第一天开始、甚至每天都是从用户界面来了解和理解这个产品,它的风格、布局、色彩和声音等等因素直接影响了我们对这个产品的早期认知和体验。UI声音设计所牵涉的知识面,几乎涵盖了任何形式的声音设计过程,心理声学、物理声学、社会心理学、人文与地理、甚至生物化学。
本文最初的动机是想猜测未来50年里我们生活中的UI声音会是怎样的。在智能手机和平板电脑普及之前,我们可能很难想象当下的交互应用场景和体验。那么,再过50年,我们的日常电子设备会是怎样的交互方式?公共空间里的交互界面会有什么声音特征?设计师会依据什么来判断应该是这样或者那样的声音?我应该根据什么来预测和判断这个趋势?很多科幻片里为了表现所谓的科幻,用了很多beep。那只是电影叙事的需要,为了让你觉得这是科幻,是一种标签化(Iconic)的设计做法而已,现实生活当中没有人会喜欢那种刺耳的声音。
当我开始深入思考这个问题、重新回顾自己掌握的知识、并且读了一些论文和专著之后,结论是:UI声音表现出来的多元性特征,本质是一个分类学的问题,我也无法准确预测50后会发生什么。这个特征也在很大程度上阻碍了相关的学术研究,其实也给我们的设计工作带来了很大麻烦,因为每个UI声音都要考虑很多的因素。本文的一个目的就是把这些因素归类,从而方便我们分析和判断。是否对设计有帮助?或许有,或许真的是徒劳。迄今位置,UI的声音设计依然是 “艺术”大于科学的一件事。这是个好消息,未来若干年里你不会被AI取代。也是个坏消息,“艺术”嘛…
这方面的专著并不是很多,仅有的一些研究成果都基于上世纪60到80年代的一些基础研究,尤其是心理声学和数字音频方面。本世纪的相关研究论文大多在2011年以前,那个时期的主要研究在“非语音UI声音(Non-speech UI Sound),其中一些研究者命名为Sonification(起名字可能是学术领域获取资金的基本功)。当然,Sonification这个词不仅仅是简单地用来描述非语音UI声音,还包括系统根据特定条件产生自动发出UI声音的机制,最初的研究对象主要在医院那样的应用场景。
交互界面的视觉和物理表现方式,包括它背后的计算和设计逻辑、思维,不在本文的讨论范围,它本身就是一门复杂的学科。本文只探讨UI声音和接收者(用户)的关系,并期冀以此给我自己和UI声音设计者一些启发。
Sender & Receiver
从运作机制上来说,至少目前我们大部分人接触到的UI,其实是一个非常简单的过程:
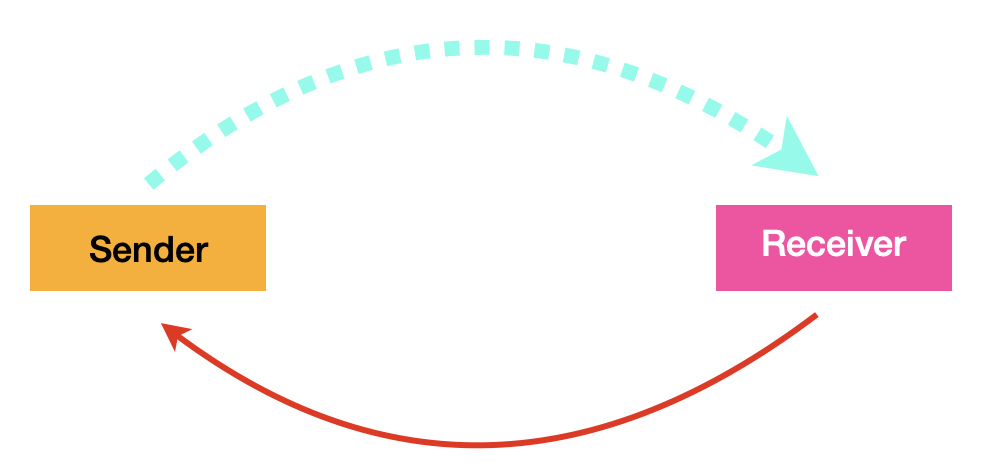
在这里,界面充当了信息发送者的角色,接收者(用户)在收到信息后返回一个信息,传统上是点击、触摸或者声音控制,并以此循环这个过程,这是一个闭环。并且,界面本身没有任何决定能力,真正的信息发送者是在视觉界面背后的东西。如图

这里的蓝色虚线表示听觉和视觉信息,红色箭头线表示不同方式的反馈。这个“反馈”,对我们来说可以是“指令”、也可以是“选择”,但对界面自身来说,这并没有什么本质区别。
以游戏中常见的UI菜单为例:
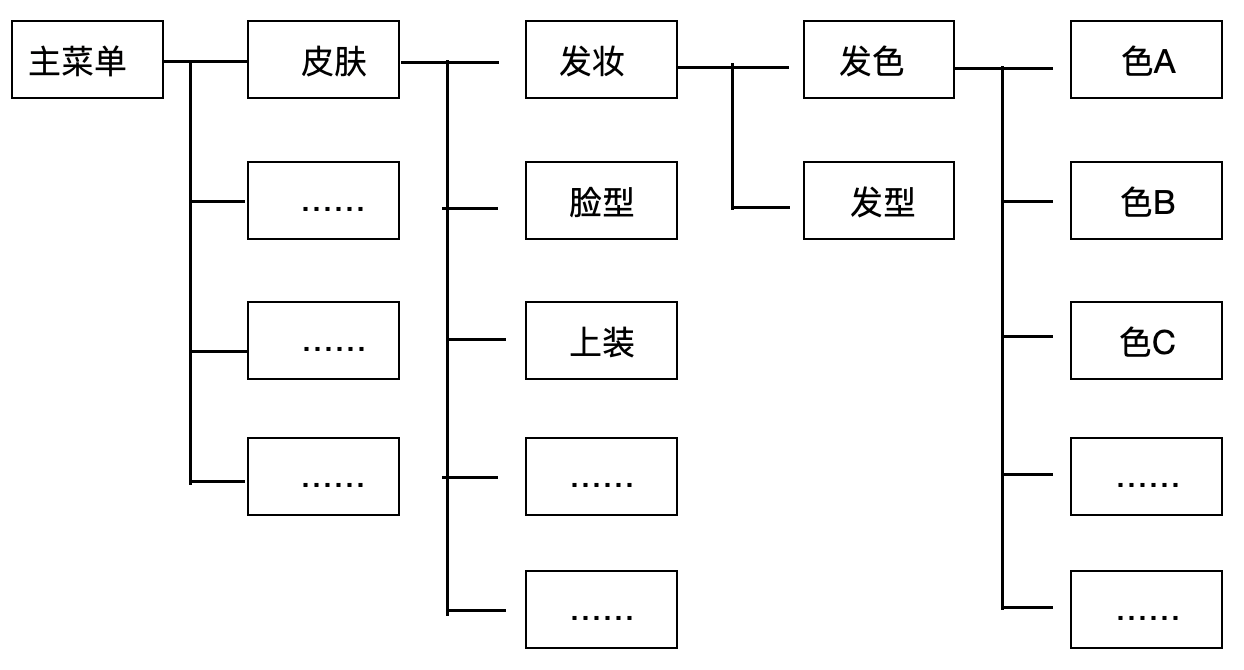
从第一层“主菜单” 到第五层菜单最终选择“色C”,至少要点击5次。如果菜单设计更复杂的话,它点击操作的次数会超过5次。如果界面设计简洁,可能只要3次。你的每一次点击,都是一个交互过程,都可能会隐去旧窗口、弹出一个新的窗口或者菜单等待你的反馈。如果每一次点击给它不同的声音、每一层窗口弹出也给它不同的声音,是否会导致声音过多产生凌乱感?为什么会产生凌乱感?如果简化声音类型,那就意味着要分类,那么如何分类?如果不分类,如何避免凌乱感?用同一个音色的不同音高可以让整体听起来流畅么?如果确定音阶?……,诸如此类的问题,本质上都会引申到分类学的问题上。即使在设计过程里不做这样的逻辑思考,在多次用户体验反馈之后,也会把你掰回到这个问题上,诸如不同UI所需要的声音性质、特征、优先级等等。因为在实际体验中,终究会浮现出一些线条,这个体验线可以帮助我们快速、准确理解界面意图、从而做出反应。那是人在交互体验时候寻求的所谓共性。然而随着智能手机、平板和其它智能终端的大范围普及,人类共有的一些本能反应,会不会逐渐地被这些交互体验影响并且发生改变?事实上,很多产品确实是在影响我们。
在一些精心设计的游戏里,菜单的层数和布局、点击的次数、窗口菜单隐去和弹出的速度,都是经过仔细考量和体验测试的。有些菜单可以用简洁明快的方式快速隐去或者弹出,有些菜单则故意用略微缓慢的方式消失或者出现,这会改变使用者的操作节奏,从而影响他们的情绪和体验。比方说获得重要升级奖励的HUD,可能会需要有力地弹出,定格2、3秒加强你的满足感,然后略舒缓地消失,让你意犹未尽。甚至有些游戏会让它停留在定格上,直到你操作退出它。声音也同样,是给一个Jingle?还是一个金币的Stinger?还是一句夸张的语音?还是三者同时都考虑使用?在一些弱操作节奏的游戏里,例如休闲养成、SLG,有些厂商会刻意减缓部分菜单的出现和隐去速度,以此来刻意缓和你的操作节奏,舒缓急切的心情,从而在心理上引起你更长时间的投入,Short break for more time。为了减缓这种刻意设计引起的不适,声音的设计会承担很重要的角色,让玩家感觉不到刻意的拖延。想一想你自己沉浸在一首歌的时候,会忘记时间的流逝。所以,这个声音的设计要求是,能够在短时间里成功转移你的注意力。恐怕这就是本文的意图:通过一些基本的分析来帮助我们在实践中思考问题。
[HUD: Head-up Display,抬头显示、平视显示。不同于可交互的UI,HUD一般定义为不可交互的内容显示,例如玩家的血量、奖励信息等等。]
UI,是一个游戏和交互App的领子,甚至是面子。它在视觉和听觉上对用户产生了第一印象,甚至每次都要从它开始,它是一扇通往产品体验的大门。
绝大部份交互产品的UI界面会包括以下几类:
- Icon
- Button
- Window
- Fader
- Number
声音可以按这种方式去分类,但大部分时候、尤其是游戏,这样做是不够的,因为它需要同时考虑多重因素。为了描述方便,本文会从两个不同的角度来分析UI声音的设计思路:Meaning含义、Feature功能。声音在媒体内容、电子设备里一定是承担了某些功能和含义,没有这个目的,这个声音是没有必要存在的,就变成了噪声。问题首先在于,我们很多时候很难判断这个声音究竟要起什么作用、甚至也不清楚它究竟会起什么作用。
Multi Dimension - Meaningful
人对”声音“的反应是很主观的,每个人对同一个声音的感受差异很大,甚至同一个声音、同一个人在不同时候的感受也不同。UI声音设计不同于其它声音的一个重要特点在于:如何找到一些共性,如何建立一些听觉共识。比如说我们听到救护车、警车的警笛声都会知道那是什么声音,你也可以非常快的速度反应过来房间里突然响起的铃声是桌上的电话还是自己的手机。换句话说,听到一个声音之后,用户很快知道、甚至瞬间就知道这个声音代表什么意思。即使你到了另一个文化截然不同的国家,即使没有刻意去记住,也能很快反应过来当地的警车声音是什么样子。
但这种现象也清晰告诉我们一点:任何声音的记忆和识别都是需要学习成本的。
这一点也不奇怪,人的听觉判断系统就像一个图书馆。甚至在你未离开母体的时候,它就已经开始工作了。任何一个声音信号,经过耳道一路传入大脑之后,大脑并不会立即”告诉你“这是什么,而是会去记忆库里搜索这个声音代表的含义,然后返回一个信号向听觉神经系统来”确认“这个信号的特征,据说依次往复要8次之多。书本上说这个过程大约、可能需要200毫秒(因为这个可以解释一个听觉保护机制,避免人的听觉系统被瞬间的大音量破坏,比如说雷声来自闪电,而一道闪电最初的形成几乎是0秒内完成的,所以我们听不到这段巨大的声音,被听觉系统的怠政抹掉了。这个理论感觉很玄乎,我们权且当它是真的吧。)。最终确认后,大脑才会从这个图书馆里拿出对应的”定义“,告诉你这声音代表什么含义,图书馆里没有的话,那就会创建一个新的告诉你(这会形成一种“新鲜感”)。这个过程,我们称为”感知“或者“感觉”,想想也非常不靠谱。在我们的一生中,这个图书馆一直都在进行学习和存储各种声音的特征、以及对它们定义。对于受过长期训练的人来说,他们的听觉图书馆里对声音的每个细微变化都会一个明确定义,因此可以辨别它们微弱、微妙的差异。但是大部分人的听觉记忆库里并不会有那么大量的存储、如此细致的分类。所以你很容易把电话里女朋友的声音记错导致挨骂,也会对电话的另一头推销小姐姐甜美的声音YY一番。甚至,你我都知道,人类的记忆能力本来就很不靠谱,很多时候需要反复被女朋友唠叨和敲打才管用,经过相当一段时间之后,你也可以像专业人士一样快速辨别出她语音的细微变化代表什么含义。尽管如此,也有很多呆子数十年也学不会。
所以,不要跟一个长期受到正确训练的专业声音工作者争论专业问题,那是在和生理学、生物化学瞎扯。确实,声音设计领域也有为数可观的人士并没有受过足够多且正确的训练(或者入错行的)。受到正确的训练甚至都不够,还必须是长期持续的。一个专业声音设计者,应当有能力辨别、设想、描述并且做出声音的微妙变化,而不是只会一两个干裂的词来表述世界的一切细微变化。
声音,在物理上只是一种震动而已。但当“人”介入之后,一切都改变了。因为人会对每一个声音下一个判断和定义,来决定它的”意义“。正如前文提到的听觉学习过程,当有一个新的声音进来之后,即使图书馆里找不到,大脑也会创建一张新的卡片,上面记录了这个声音名字和含义,这个过程是非常主观的,甚至卡片上的信息也会不断更新。大脑也可能会拿错卡片。那么,像警笛、救护车之类的声音,我们为什么可以达成一个普遍的共识?是因为影视、各种媒体和我们的生活经历让我们能够把这类声音与它所代表的声源对应起来,甚至还会让你联想到声源背后更多的信息,比如说“哪里出事了”。我们的生活中有很多很多这样具有普遍共识的声音,成为大大小小社会圈子的共同记忆。
对与声音设计师来说,UI的声音需要能够在尽可能短的时间里让绝大部分用户知道它代表什么含义,并且能够记住。
关键词:含义,记忆。
一个声音的含义,可以有很多方式来表达。在一个动画片里,变形金刚一边喊着号子,一边出现咔咔咔咔变形的声音。无论哪个角色,咔咔咔咔多次重复之后你就知道了,但是你还是需要看着画面、听着它的号子来判断究竟是哪个角色。画面和语音都指出了它的对象是什么,而咔咔声只是代表了一个模糊的概念,但是非常简单,几次重复你就记住了它的音色Timbre、节奏模式Pattern。这是一个抽象的代入方法。
但是,你恐怕很难在真人电影版里记住、甚至描述出这个变形的声音特点,因为电影版里变形的声音有太多太多的细节,一连串音色以复杂多变的速度快速变化,让你觉得非常酷爽,但是完全无法用简单的口技来重复,你最多也就能在脑子里保留一个模糊的概念,让你在下一次听到这个声音就能反应过来那是什么。让你感觉酷爽的原因主要是一个:高密度、丰富的声音有效地组合起来,瞬间灌满你的意识,让你没有机会和空间去想别的。但是为了强化你的记忆,电影版还是用了几个密集的、充满同一种金属材质的重音形成一个Pattern。
所以,通过一种简化和抽象的方式,让人更容易记住它的音色和表现模式,并且通过它来指代某些相对笼统的概念,从而更容易记住它所代表的含义。这是所有UI声音设计都逃不过去的方法。
关键词:音色Timbre、模式Pattern。
对于UI来说,一个音色的选择受制于一系列的因素,至少包括:
- 产品整体美术风格
- UI界面美术风格与特点
- 剧情或体验特征
- 交互目的
- 交互方式
- 交互速度、频次
- 交互体验的情感、情绪因素
- 设计师或者产品开发组个人喜好
这些因素是我们开始寻找抽象代入方法的起点。
产品整体美术风格大部分交互产品,无论是ATM机、手机、App、还是游戏,都会存在一个特定的美术风格和整体视觉特征。这个视觉特征是整个产品目标的一部分,包括:目标人群社会特征、产品的个性以及它的使用方式等等。比如过ATM机的设计必须能够适合绝大部分在没有指导的情况下使用,它必须耐用、安全,不容易让人轻易产生非分之想。而手机、游戏的美术风格可能就是想让你冲动一下。所以,在声音设计的开始阶段就需要建立一个“视觉-听觉”的联结:用什么样的听觉体验来配合视觉来强化整体体验。这一点有时候很难,几乎取决于你的知识面和理解力。如果你的大脑听觉池子不够大、不够深,那么就要做足够多功课了。
UI界面美术风格与特点UI界面的美术风格和视觉特点,通常来说无论在配色、布局还是材质的选择上都会力图和整体产品美术设计保持统一,因为那样看着“顺心”、更容易理解或记忆。但也有很大可能会出现截然不同的风格,而目的通常是为了让你感受到UI的存在感。比如说一个三国题材的SLG,主菜单的美术可能要体现极简主义的现代感、科技感,目的是为了让吸引年轻人…(真不知道这个推理怎么来的,跟极简主义、科技感和现代感有仇)。通常这样的反差和迥异设计,是为了刻意地让玩家从游戏剧情和体验里临时抽离出来,因为主菜单里可能有一系列的操作需要你换一个心情来做会做得更好、停留时间更长(这是我猜的)。无论如何,在一个能够充分自洽解释的情况下,UI声音的音色选择会需要同时考虑“兼容”两者。而这个“自洽”,可以来自项目,也可以来自设计师自己,但最终需要在体验上表现出来。
剧情或体验特征在很多网络游戏里,剧情往往是首先被忽略的,甚至是可以支离破碎的。而在单机游戏里,剧情和电影一样是承载游戏体验的一条船。你从ATM机里获得的快乐和幸福感是它吐出来的现金,它长啥样子都可以。但是站在ATM机前操作的时候,你可能也是有点激动的、忐忑的、无奈的….等等各种情绪,这种情绪是你自发的,和ATM机没有关系。一个App或者一个游戏,那就不一样了,它们必须是有预谋地勾起你的欲望或情绪。在单机里,它可以是相对更加完整的剧情线、更加影视化的音乐和配音,声音有机会和美术一起更加影视化地营造出一个让你逐渐沉沦的长线条体验环境,让用户进一步体验剧情的一些背景、游戏的体验的背景、甚至是视觉里无法传达的内容体验。而网络游戏的根本在于人和人之间的互动,两者的体验重心有着本质不同。但在UI设计上,两者还是大体相同的。比如说当你按下“开始”按钮的同时,会出现一个短促的Stinger,紧接着出现一辆跑车猛轰油门的声音,就会让你在理解这个游戏目的的同时调动起情绪,如果同时叠加一点警笛声,会让你瞬间联想出更多的内容,从而产生期待。Stinger给了你一个有力的按键反馈声,轰鸣声让你感受到力量的积蓄、警笛声可能让你想到你被追或者你追人家。对于剧情和体验特征的深刻理解,可以让你有机会找到足够抽象和简约的方式来规划UI声音的走向。而网络游戏可能需要考虑更多的是,你加入和他人协作或者对抗时候的情绪是怎样的,你在进入那个开放世界时候会是怎样的心情?玩了一周、四周之后会是怎样的心情?这不仅仅是一个体验预测,还是需要设计师是去创建的体验。
交互目的交互目的,这是一个非常关键的事情。它可以是:我为什么要玩你这个游戏?也可以是,这个游戏想让我玩什么?这是很多产品做着做着就彻底忘记的事情。任何一个交互行为,都是有目的的,声音需要能够表现出你交互的结果和目的。同样的按钮,不同的交互目的,会带来截然不同的音色选择。这包括两层含义:对象自身的含义、对象交互后结果的含义。比如说当你按下一个OK键之后,它会紧接着弹出下一个选择窗,也可能退出菜单。那么,你会首先需要考虑这个OK键按下去应该是怎样的音色听感,即使一块石头样子的OK键都可能有100种选择。但是,考虑到新弹窗出现的音色和OK按键音色保持一定的协调,也要考虑如果是退出菜单的情况,那么你的选择范围就会小很多。这个“协调”,可以是形成像打击乐器一样的音色对比节奏模式,也可以是其它形式的。这么做的目的,一是可以抽象、形象地向用户反馈操作,而不只是发出一个声音;二是降低学习成本,让用户可以快速记住这个声音出现意味着什么。
交互方式大部分产品交互体验过程里,交互的方式通常都非常简单直接。就像我们点开手机里一个App一样。但是想一想,同样的一个“OK”按钮,鼠标点击、和手指触碰,是不是同样的感受?如果是游戏手柄呢?况且,在VR、AR和未来可能的其它交互方式里,会产生更多不同的交互方式。很多游戏手柄是有力反馈的,当你开始射击的时候,它会产生相应的后座力反应,来强化你的操作体验,你就能感受到更多的射击体验和乐趣,因为拟真体感带来了更多的“代入感”,这时候可能枪声的低频Boom就不需要太多,因为视觉和手柄力反馈已经给了足够的刺激。但是,鼠标一般不会有力反馈,所以略大一些Boom层可能会改善体验。然而在手机上,如果让手机产生震动来达到这种拟真,就可能完全没法瞄准了,而且触碰式的操作在这种情况下显得非常无力和疲软,使不上劲就无法释放用户此时的情绪,所以更大的枪声就变成了最简单廉价的方式、甚至唯一的方式来映衬和助推玩家的体验。UI也存在同样的问题,只是更容易被我们忽视。
交互速度、频次交互速度和频次会非常直接地影响音色的选择,这是大部分略有经验的设计师都有过的经历,尤其是交互频次。即使在夜店或者乐队现场,他们也会通过编排过的方式引导你,而不是一味地轰炸你的听觉,因为听觉是非常容易疲劳的。高频次出现的交互动作,通常都会、也应该是考虑尽可能避免刺激性的声音,而选择轻柔的。不过,有时候因为游戏体验的复杂性,在某些情况下这个声音必须要足够强的刺激性,同时也可能会连续出现,这种情况往往会出现在HUD里。这种条件下,首先需要考虑的是交互目的究竟是什么?为什么需要强刺激性的声音,是增加记忆度?还是强化情绪?你有很多方式可以避免使用强刺激的声音来达到同样的目的,比如说一段Jingle、Attack较慢的重音、合适的语音等等。同时,也需要考虑交互的速度,越是利落的声音,会让人不自觉地提高交互速度。但是在某些页面或者HUD显示的时候,如果适当出现一些略微舒缓的声音或者一段足以引导玩家释放情绪的Jingle,可以有效减缓交互速度,如果游戏体验上需要的话。甚至,你应该和UI美术设计、游戏策划共同商量重要UI环节的体验线。
交互体验的情感、情绪因素情绪和情感体验,其实是一个生物化学反应。大脑的听觉记忆库在拿给你小卡片的时候并不会让你产生任何情绪,而只是一些信息。当听觉毛细胞把信息传给后脑之后,后脑将收到的信息过滤后发给中脑;中脑会将收到的各种信息整合起来之后再发送出去。其中,丘脑承担了非常重要的“信息分发”任务,它会把不同的信息发送给大脑的不同区域,而前脑负责控制你的有意识行为。任何一个游戏或者app或者其它交互媒体,它需要一点时间的累积、通过一系列的诱导因素才能能引起情绪和情感上的反应。所以,它一定是一个多种因素混合的综合性结果。用户可能会举出一个例子来告诉你TA有什么样的情绪反应。但作为职业设计师,我们需要比较客观地看待TA的举例以及TA对自己情绪反应的描述,分析背后的成因。在体验过程里,情绪和情感反应在大部分时候是通过听觉、视觉或者两者的合作去触动你的共鸣,让你能够在意识上放弃心理戒备并且投入在它们营造的环境或者气氛里去,而不是某个单一因素引起的。假设有用户说就是其中的某一些声音打动了TA,那其实可能是个案,只是这个声音对TA个人来说存在一些情绪共鸣点,很可能并不具备普遍性,但也可能具备普遍意义的潜力,我们需要学会去分析这一点。这取决于你的声音普遍共识的理解,换句话说“职业阅历”,也取决于你的知识范围和思考。
而UI的情况比较尴尬,它会受制于一系列的因素,我们很少能像音乐一样通过声音来获得直接或者明显的情绪反馈,而HUD因为使用明确情绪倾向的Jingle之类的声音或者某一句重复多次的台词,反而会让你的情绪反馈比较明显,并且有些HUD的出现时机恰恰是你完成一个阶段任务之后出现的,用户已经积累和具备了一定的心理积累。比如说刚拿到自己的第一台PS5,它系统界面的声音都可能让你觉得兴奋。原因可能是两点:你的热切期待已经积累的一些情绪;你对新系统界面音效的新鲜感,就像一根火柴,瞬间点燃了你这根干柴。在你玩了一段时间、听了很多很多次PS5系统界面声音之后,你的情绪就不会再像第一次开机时候那么兴奋。而时隔多年之后如果你再次遇到一台PS5,或许会很快勾起你无数的回忆。这个例子中,情绪的最初积累并不是来自PS5系统的声音,而是对PS5的期待,PS5系统界面的声音只是一个诱因,但你也因此建立了一个听觉情绪关联。声音在很多时候不仅仅充当了一个强化“代入感”、让你觉得写实、有趣或者情绪累积的任务,而是让你的诱发你的情绪释放(累积和释放,是两件事情)。并且我们也知道,受众的情绪远比“喜怒哀乐”四个字多样化,这四个字只是非常非常粗略的概括。在产品设计过程中,我们恐怕不能只看到这些基本的概括,更要关注一些细分的情况,比如说接住梗的窃喜。什么样的喜、什么样的悲、什么样的哀、什么样的乐,都是设计师需要精心布局的。我曾经遇到过一些项目,除了一个“爽”字,就没有第二个词来描述自己的意图了。可能是词汇表达实在有限、可能真的是这样想的。“爽”的体验是一个非常模糊的概念,很多时候它是一个接近语气词的表达,并不是一个相对准确的情感描述,就像我们说“酷”一样,可以指代任何一种可能的体验反应。当然,这也不可能因为其中一个声音显得与众不同,就会觉得整体体验也会与众不同。作为专业人士,我们需要了解非专业描述的背后究竟包含什么。
这个问题当然也会受到游戏体验、美术风格、甚至剧情的某些特殊性的影响。美式卡通和日式卡通不仅仅在视觉表现上有很大区别,两者都表现出了鲜明的标签化(Iconic)特征,这种特征本身可能就会给不同的人群带来情感和情绪预设。在声音表现上,这种特征也是标签化的。但这种“标签化”几乎不太可能通过一两个独立的声音样本来表现,也鲜有可能通过一些形容词甚至技术角度来清晰描述,而是需要一系列的声音组合起来才会让你感觉到。如何判断一个声音是否是“标签化”,取决于你对风格化内容的了解范围和深度,比如说Star Wars里有哪些角色的声音是星战粉津津乐道的,即使你不是星战粉,也是需要去了解的,甚至要清楚那些声音最初的制作方法、以及现在的制作方法,甚至需要自己动手仿照原型做做练习,那是你工作的一部分。因为那些声音代表了一个小文化圈、一类人群的口味,它是带有明确情感因素的,受众能够轻松接住你设计的梗,从而引起不同的共鸣。当然,如果用错梗或者梗歪了的后果可能也会很严重。
和一本有趣的小说、一部有趣的电影一样,故事是需要精心构、铺垫和布局才能最大程度引起你的情感共鸣,声音的情感情绪设计也一样。我们看完剧本、看着UI的美术方案之后,需要从音乐、音效、台词语音、营销策略等各方面来分析所有的可能性,然后把UI相关的元素排列出来。这个过程,有人描述为“remapping”,我觉得很恰当,这是一次“布局”。
- 情绪累积和释放,是两件事情
- 情绪和情感远不止喜怒哀乐四个字
- 情绪累积和释放,需要合理布局
声音设计师也是一个Sender,TA需要来考虑如何当好一个Sender,并且预测Receiver的反应、甚至有预谋地让Receiver跟随你的布局走。这个布局,除了情绪,还可以是Timbre音色、声音模式Pattern,甚至是功能。
Multi Dimension - Feature
谈到Feature“功能”(其实也可以理解为 “作用”),我们往往第一时间会想到的是“技术”。技术无论在内容制作还是交互数据实现过程中当然是一个非常重要环节,它决定了声音以什么方式传递给用户。但不是本文要讨论的。
不同的UI声音可能会承担截然不同的功能角色。如果一个UI声音没能够起到该有的功能作用,那么这个声音无论你自视有多 “好听”就是有问题的,这是UI声音设计的最主要前提。这里说的“功能”,也远远不止于上文提到的“交互目的”,而是完全从另一个角度来分析UI声音分类和布局的可能性。
这个“功能”可以从多个不同角度来描述,我们需要了解它们在交互过程中会起到哪些具体的作用,我们有哪些角度和方式可以来描述,以及具体是什么声音因素在影响我们的交互体验。如果说上文中提到的是一系列抽象的、没啥直接帮助的概念,那么功能分析可能是每个设计师都需要熟练掌握的。
首先,我们为什么要给UI互动操作一些声音?答案是:即时听觉反馈,Real-time Auditory Feedback(RAF。我也造一个缩写,体验下学术的矫情)。这是UI声音的本质功能。这里包含两个词:听觉和即时反馈。那么声音需要反馈些什么?我们先来看看声音在传统媒体和交互媒体里的基本作用(不分等级或者先后):
- 降低视觉信息的承载量:合理分配视觉和听觉信息的传达量
- 完善甚至重建视觉信息:听觉可以让悲剧变成喜剧,也可以让喜剧变成悬疑剧
- 视觉受到了空间限制:视线转移了、画面快速切换了…都需要听觉来保持理解的连续性
- 听觉能够传达更多信息的时候:如果眼睛能够解决一切,那就不需要语言了
- 转化情绪:音乐可以告诉我们如何理解一段画面以及它的情绪
- 屏幕尺寸受限:声音可以拓展屏幕表达的局限性
视觉和接触交互总是需要在UI界面你的视觉范围内,它们有一个空间限制,而听觉的空间自由度要高很多很多。即使你背过身去,依然可以和Siri聊天,那是声音和听觉。这也是为什么行车导航里语音功能的使用可能比打游戏开声音更普遍的主要原因,因为那是安全性刚需。在游戏过程里,你的注意力可能会集中在屏幕内容上,这时候听觉就可以承担一些视觉无法很好呈现的功能,比如说远距离偷袭你的人、你的弹药量。在那些三消游戏里,我们需要视觉集中注意力来帮助我们快速判断状态,这种状态下,人的情绪累积因素可能会趋向单一化:急切和紧张的闭环。然而一款真正有趣的三消游戏,并不会希望玩家长时间沉浸在这种单一情绪闭环里,而是有更丰富的体验。听觉在这时候就可以承担起作用,它或许可以调剂和舒缓情绪、或许可以拖住你的操作节奏。我们的听觉体验节奏其实非常容易被带走,这是视觉无法做到的,听觉在这里也不是视觉的辅助,而是和视觉平行的功能线。电影的配乐,很多时候是在告诉我们怎么理解这段画面和剧情。其实整个电影的Soundtrack都是在起这样的功能。
但是声音的空间自由度也会带来负面的作用:私密性。当你听到这个声音的时候,边上的其他人也能听到。并不是每个人都想听到你手机喇叭传出来的歌,你也可能不希望别人知道你在操作什么。所以很多人的手机大部分时候处于静音状态,甚至在游戏、这种强交互的产品体验时候也会关闭声音。有些ATM机的声音不知道为什么就是很大,似乎每次都想大声告诉人家我在取钱。
即时反馈几乎是所有UI交互闭环一个重要特征,因为这是它存在的必要性之一。声音也不可避免需要配合做到这一点。很多时候,它会伴随视觉界面同步行动,但有时候它也可以独自行动。因为UI无论如何都是为了向我们传达一些必要信息,这些信息主要可以分为几类:
- Event事件:发生了某些特定的事情(比如说队友出局了或者你进入下一关了)
- Status状态:发生了某种状态的变化或者状态持续的情况(比如手机充电过程),这通常是一种汇报信息。
- Offer提案:提供一些特定的选项、建议或者请求。
- Message:显示一些特定消息(比如说在局外养的蛊熟了)
这四类信息中的每一类,都可能会有重要信息和次要信息。重要的信息理所当然需要即时引起用户的注意。无论在美术、体验还是声音设计上,哪些信息重要、哪些次要,是需要规划的,不可能一股脑扔给用户。过多的信息传递一定会被用户忽略,就跟你老母亲跟你唠叨别人家的孩子一样烦人。这里的“重要性”,虽然是由系统或者设计者来决定的,但设计者需要从产品体验和受众体验目标里来判断每个界面和互动操作的重要程度,其中包括信息本身的重要性。对用户而言,这也可以称为“关注度”。比如说从字面意义上可以分为(从高到低):
- Alert
- Warning
- Attention
- Message
- Tips
这种方式明显带有上文提到的情绪性,你也可以用别的方式,比如说Focus Level 1-4。
根据UI声音的基本性质,也可以有另一种简化的分类方法:
- Attention:希望用户关注的声音,你可以在这个类别里细分优先级。
- Intention:只是一些补充信息、次要信息
- Tendency:单纯从功能或者声音设计角度来决定需要特殊处理的声音
依此类推,UI的声音在听觉上的作用也可以归纳为:
- Identification:定义UI对象以及它的性质和属性
- Clarity to perception: 澄清和明确UI交互感知体验
- Modulate the behavior: 促使用户改变或者调整UI交互行为
- Spatial Location:传达声场空间和位置
Identification
无论一个UI界面是Event、Status、Offer还是Message,都是为了告诉我们它是谁、它表示什么意思。 “性质”也包括它的重要性、关注度、含义等等。UI的声音必须有能力在第一时间传达出来,甚至需要帮助视觉设计来向用户定义它的性质和属性定义。简而言之,它必须在视觉和听觉上告诉我们:我是谁、我来自哪里、我在干什么。这是UI的美术、声音设计首先要做到的一点。如果视觉上已经能够清晰呈现交互的对象和目标,那么这时候声音可能就不需要高饱和性地去澄清或者强化这个信息,那就能给这个声音带来更多的发挥空间。你可以选择进一步强化(画内、画外都可以考虑),也可以更多考虑某些情绪色彩,取决于这个声音的所处的“语境Context”。
在这个问题上,有一点非常重要:过多的定义表现,会增加用户的学习成本。对于听觉来说尤其如此。上文介绍过,人的听觉判断主要来自听觉记忆。除非这些声音呈现出清晰明确的规律,例如强弱明确、音色特征鲜明。这也是为什么我们会尽量简化UI界面声音元素的主因,比如说所有的图标点击都共用一个声音,但与此同时这个点击声音的选择不得不考虑诸多因素,这也是设计的一个环节。
Clarity to perception
有时候,视觉体验本身因为美术、交互方式等限制,无法更加准确清晰地传达它的含义和性质,或者无法在一瞬间让你了解它的本意,那么声音的一个作用就是来澄清和明确这个信息的属性和性质。一个最简单的点击动作在整个交互闭环发生的时间里,一般会包括窗口点击、窗口转换或弹出、再点击和关闭四个阶段。这个过程的两个声音,不仅仅在告诉我们窗口弹出和消失这两个事情或者说状态,那只是在澄清窗口的状态。但作为一个经过设计的声音方案,它们还需要能够体现这个窗口的一些体验特点。例如Mac OS的垃圾桶,当你清理垃圾桶的时候,它不仅仅给了你一个声音告诉你现在垃圾桶清空了,揉纸团的声音形象地告诉你这是“垃圾”和“废物”,这个声音并没有让你感觉是一下子飞快有力地揉纸团,而是分了两下来揉,足够让你听清楚淡定揉纸团的过程,却不需要很亮或者很大的声音,但足以澄清这个含义。手机的闹铃功能就是个很好的例子,闹铃的首要功能目标是让用户起床、其次是提醒用户某个预约事件。从用户关注度来说,当然是起床声音需要大一些、刺激一些才能让熟睡的用户醒过来。但是如果是会议预约提醒也是那么刺激的话,很可能会打扰边上的人。我曾经遇到过,有同事手机里的电话铃声和我的起床闹铃是一样的声音,每次他的手机一响,哪怕很轻,我都可以瞬间从昏昏欲睡的会议里清醒过来,甚至有蹦起来的冲动,而其他人看起来就像什么也没发生一样。可见,听觉系统在学习和适应了某个声音代表的含义之后,是可以形成明确的听觉记忆、并且产生生理性的条件反射,这个反应是需要培养的。同样,声音的澄清作用是也是可以培养的。
Modulate the behavior
前文提到过关于通过UI声音的节奏来逐渐影响人的操作节奏,那只是一个比较典型的例子,并且是需要精心布局的。通常这样的局,会在项目的中后期来筹备如何下套,因为那时候UI体验通常会比较完整一点,你有机会坐下来从个方面考虑这个问题。但这个问题也需要在项目的前期来考虑这种可能性,从而让相应的BGM给音效留出足够多的空间和可能性。当然,UI窗口本身的美术设计布局也是至关重要的,毕竟这种情况是需要视觉和听觉协同才能起到最好的作用。有一些日本游戏,会故意把同一个窗口能够显示的信息,分成两个窗口先后出来。因为同一个窗口不宜显示过多的信息,否则会让用户遗漏最重要的内容,从而降低信息接收效率。在这种情况下,声音也需要一起来配合。如果过大的、过于刺激的声音可能会干扰用户在短时间里集中起注意力来关注那些重要的信息和反馈。因为有些页面就是为了让用户充分关注到那些信息细节,才会推动他们理解和体验游戏的目标。这是一个经过精心设计的局,知道用户在看这些界面的时候心情是怎样的,或者说你、作为设计师会希望用户在看到这个界面时候产生什么样的情绪和反应。这可能是UI美术、游戏策划和声音设计都需要认真考虑的问题,而不是简单地duang一声扔出一堆选项和数值。这也不仅仅是产品体验,还涉及到产品的表达细节以及商业策略,影响交互节奏也仅仅是其中一种可能性。不同的交互操作方式,也会根本上影响对UI的体验,从而影响声音的设计方向。高亮某一个选项按钮的时候,如果是鼠标,那是一种“点击”甚至只是简单地把鼠标移到它上面。但如果是手机或者平板,那就是手指的触碰。如果是手柄,当你按下方向键的之后,只是看到对应的按钮亮了,这个过程是相对间接的,有点像遥控车。鼠标移动高亮,声音的音头可以比较软,以避免光标快速扫过之后会带起一大堆声音;但是手指触碰,我们可能需要给这个触碰一个即时明确的触碰感、触摸感,甚至是按动核爆开关的感觉;如果是手柄,因为是相对间接的互动,所以它的声音选择范围确实可以大很多,你有机会从更大的范围里考虑这种交互体验所需要的声音。但无论如何,交互方式本身、以及交互对象的即时操作感受,是我们需要充分考虑的。我们在设计的时候,需要尽可能多地考虑用户的使用习惯、使用场景。有些习惯是目标用户已经具备的,有些则是需要培养的。我们很容易忽略的事情是:用户在看到和操作这个界面的时候会是怎样的情绪、以及什么样的场景。
Spatial Location
这一点,主要是指AR、VR类的交互体验,但也有越来越多的游戏和App会设计3D化的交互界面。这时候,UI声音面临的挑战首先是解决它在声场空间里的3D声音定位问题、以及它们的属性如何充分体现。就目前已有的技术来说,这不是一个问题。麻烦在于你如何把握这个3D的度,比如说是否需要距离衰减、衰减距离和曲线怎样、是否需要LPF….等等细节问题。这些问题都只和两点有关:
- 这个3D界面是否需要3D的声音?
- 这个3D界面是要向用户传达什么?
第一点,相对来说是比较容易确定的。但其实很多时候,是第二点决定了它是否需要3D化的声音。很多采集游戏和FPS游戏会在地图里随机释放各种物件,当你经过的时候系统会跳出来告诉你那是什么、以及它的一些简介。有些游戏会把这样的窗口做成3D的,这个时候如果声音是2D的话,可能会造成视觉听觉的不协调;如果处理成3D的,可能会听不清楚。但“听不清楚”在这种条件下重要么?恐怕音量并不是很重要,因为视觉上已经明确告诉你它的位置了,大脑会帮你建立一个联动体验,你并不需要很大的音量或者很亮的声音就可以达到目的。这个弹出的声音主要一个视觉体验的加强或者澄清,其次才是让你有一个机会来表现它的含义和3D位置。另一方面,就已经习惯了2D UI界面的用户来说,3D化的界面声音可能也会让TA需要一点时间来适应,尤其是聆听环境不是那么好的话。我们大部分人的听觉系统,对于双耳前方的声音在定位、距离判断准确性上要比脑后的要强很多,尤其是高度信息。而头顶和脑部下方的定位精确度就更弱了。在双耳前方,有些人能够辨别出1度的变化,而其他方向上基本上只有10度的精度。所以目前没有一款耳机能够很好呈现多声道定位,尤其是高度上的变化、以及脑后的声音位置,尤其是相对静态的或者运动空间比较小的声音。影院里的Atmos系统尽管在天花板上也分布了音箱,但也需要一定的空间高度来呈现它在头部以上的位置。通过耳机来呈现,无论厂商的歌怎么唱,目前还只是一个Binaural的立体声而已。
这个问题还涉及到第三点:空间Spatial。很多时候,听觉要比视觉更容易表现出一个空间感,因为它可以突破视觉范围的局限性。在大部分人的听觉系统里,声音在不同空间里的反射、衍射已经成为他们对声音认知体验不可分割的一部分。而对于专业声音工作者来说,混响声Wet和直达声Dry是割裂的两件事,是可以用来揉捏之后忽悠用户的手段。然而,Reverb在带来空间感的同时,也会造成响度的提升(请看下文),甚至会造成声音听感变形。其实绝大部分UI界面可能都是干声,只有一些经过精心设计的产品,才会小心翼翼地给UI声音一些混响,这个做法主要是通过构建一个空间感,来产生一个代入感、或者说所谓的沉浸感。沉浸感是一个包含了视觉、听觉、甚至味觉和触觉的综合性体验和感知,听觉只是其中一个的重要组成部份,沉浸感也不等同于空间感。(其实这是一个很大的话题,好在这方面的技术目前发展缓慢,还处在很原始的阶段,我还有时间去学习。)
UI界面大部分都是干声,是因为它需要把你从虚拟现实中拉回到现实中来。而有时候我们会希望用户在UI界面操作的时候继续停留在虚拟现实当中。从技术角度讲,其实很多精心设计的游戏是给UI一些混响、甚至其他效果的,那并不是为了产生虚拟环境,而是从听觉舒适性和整体混音平衡的角度出发的。
继续观看下篇:https://www.midifan.com/modulearticle-detailview-7035.htm
转载新闻请注明出自 Midifan.com
-
2021-02-21 22:01
 匿名
非常有用的文章~
匿名
非常有用的文章~ -
2021-02-21 22:01
匿名
非常有用的文章~
-
2021-02-17 07:57
匿名
非常棒
-
2021-02-17 00:33
匿名
好文,期待下期。