还嫌人声「不够大」?7 个 Waves 插件使用技巧帮你实现
如果你做流行、摇滚、嘻哈、EDM,甚或爵士乐,你可能会想要那种令人垂涎的“贴面”的声音——反正不是你的客户想要,就是你自己想要。响亮的人声并不一定很容易得到。这倒没有什么秘诀,而是可以在合适的情况使用多种合适的技术来实现这一目标。

文:Matthew Weiss
如果你做流行、摇滚、嘻哈、EDM,甚或爵士乐,你可能会想要那种令人垂涎的“贴面”的声音——反正不是你的客户想要,就是你自己想要。响亮的人声并不一定很容易得到。这倒没有什么秘诀,而是可以在合适的情况使用多种合适的技术来实现这一目标。
1. 从源头就录好
这一点有点儿“陈词滥调”,但真的不得不反复强调。从非常圆满的录音起步,会使整个过程变得更加容易。在制作的任何环节,都有可能偷工减料一下。然而:我不想在人声上这么做。如果你家里没有高大上的“武器库”,那么即使只是为了录人声,租一间好棚也是值得的。这能让你控制录音。如果你没租棚录音,我们下面也会讨论到用混音技术来弥补。
2. 提电平,在正确的位置做衰减
现在,假设人声已经录得很好了。获得洪亮声音的一个最简单方法就是简单地提高人声轨道电平,直到它逐渐“居于”音乐之上。由此入手,再用一个好参数均衡器——SSL E-Channel通道条是个不错的选择。
很有可能,某几个特定频段过于拥挤。这是在物理空间中录制人声的一种自然效果。话筒、话放、房间和人声本身都可能会在几个地方产生一些频段叠加。这些频率堆积往往是相当明显的。通常的“罪魁祸首”是房间声的中低频,还有话筒近接产生的低频。但由于这样或那样的原因,频谱中的任何地方都可能出现类似情况。这就需要仔细听。在正确的位置进行一点衰减,会大大帮助平整频率堆积,使人声重新回归正轨,即使它音量很大。
3. 克服音色的不一致性
要保持人声饱满且靠前,更棘手的问题是,随着时间的推移会出现不一致的音色。歌手在欢唱的过程中,可能会突然唱呲一个音符——因为脖子过度紧张,或者离话筒太近,又或正好唱在某个咝声辅音上。对于最终听众来说,感觉就是本来人声优美饱满又靠前,但突然唱片“跳针”了似的,大煞风景。这时,我们就得用到“电动打磨机”——C6多段压缩器。
“多频段压缩”这个词有时可能令人畏惧,但如果你只是将其想象为平衡音色不一致时用的工具,那它用起来实际非常简单。如果声音中存在太多1.5 kHz的频率,常规EQ就可以应付。但如果歌手改变了与话筒的距离,有时就会出现太多低频——我们就应该进行多段处理了。
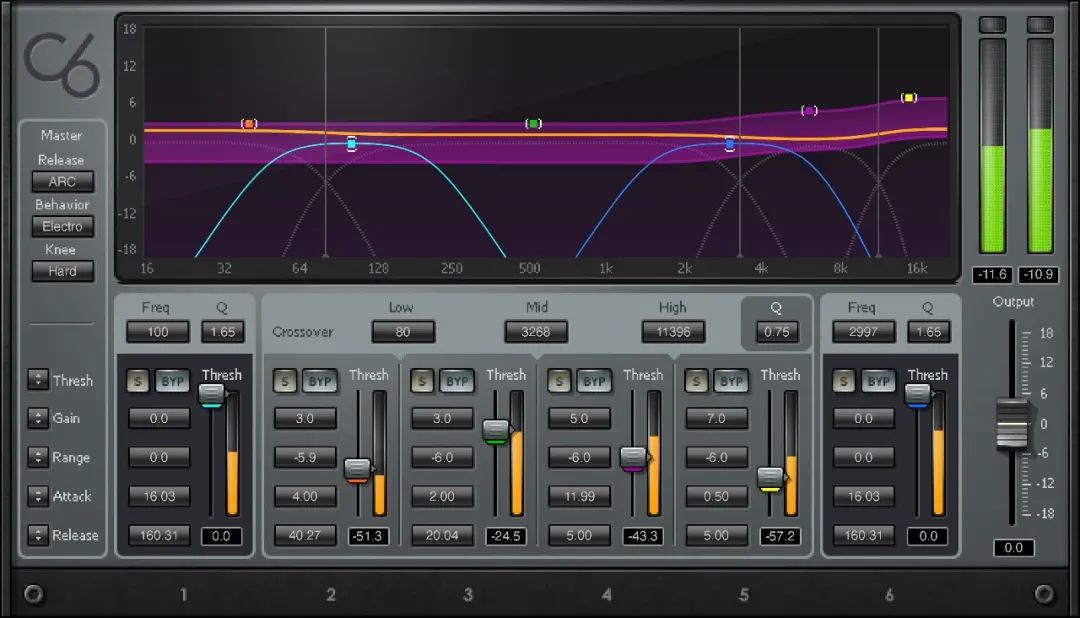
C6多段压缩器
当然,我们始终以分离频段的DeEsser去齿音形式来使用多段压缩。分段去齿音只是一种专注于高频范围,且反应快速的多段操作。相对而言,常规的多段压缩会是更宽泛、更灵活的应用。
因此,如果你的声音优美而靠前,但偶尔在中高频上过于尖锐,就请打开C6,把问题频段隔离开,将压缩器触发点设置在刚好人声冒出的位置。
或者,你还可以尝试用动态均衡器来做这件事。其结果有些相似,但实现目标的途径则有些不同。F6动态均衡器有6个浮动EQ频段,你可以将其设置在超过每个频段阈值时启动。这样,你就能得到参数均衡曲线,而不是像C6那样通过分频点隔离声音。选你自己喜欢的方式就好——控制方式不同,结果差不多。
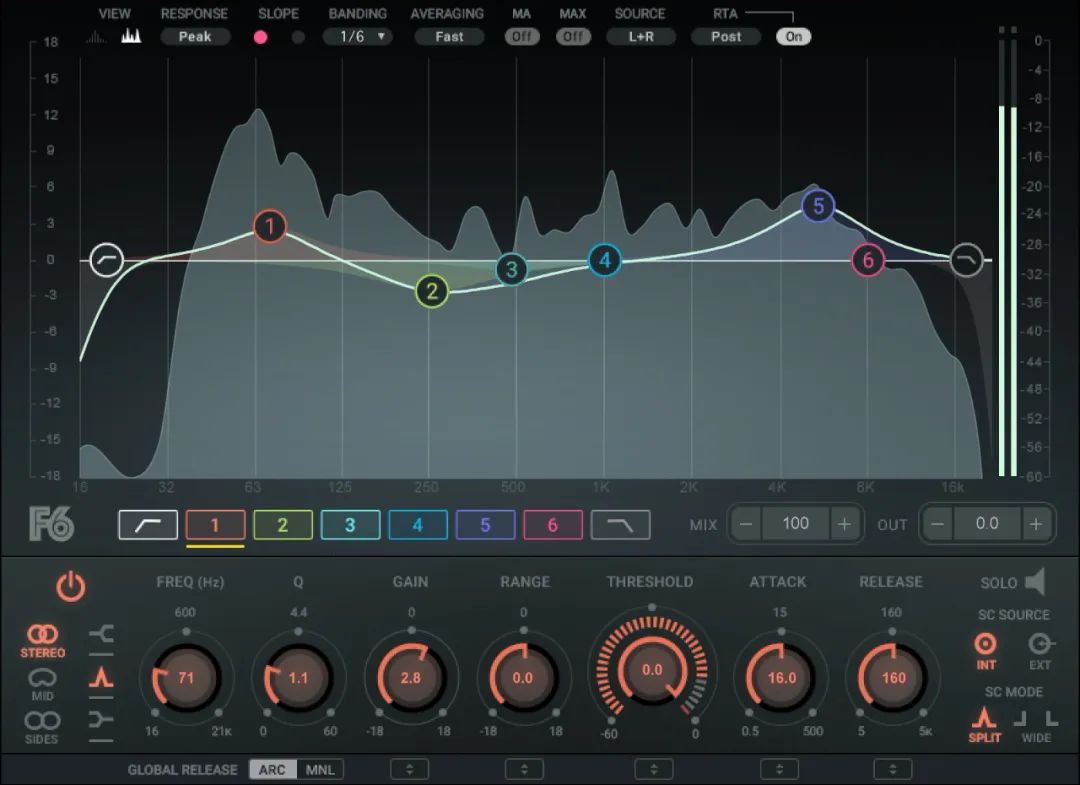
F6浮动频段动态均衡器
4. 3个阶段“让压缩充满爱”
可能有人会想,为什么压缩在这里居然排在第四点?这是因为压缩并不是获得“贴面”人声的真正万能解决方案。我很看重音色曲线:如果你没有做出正确的均衡,任何压缩都无济于事。而一旦我们整好了EQ曲线,就可以灵活运用压缩了。我喜欢分阶段地处理动态:
- 对我来说,第一阶段是手动电平编辑。在大多数人声表演中,歌手都会有那么一两下能量爆发。抓住那些点,在插入压缩前做适当衰减,可以有效控制。
- 然后,我将关注演唱风格。如果人声表达得很流畅,我可能想要一些能够温和地平衡声音的东西——选择更慢、更通透的压缩。CLA-2A是个很好的选择,或者Vocal Rider(尽管从技术上来说它不是一个压缩器)。如果人声断断续续或有打击乐的节奏感,我就要用可以在不过度摇摆的情况下稳定那些辅音的工具。这时,用CLA-76或R-Comp都可以。
- 最后的阶段是微量的“强力”压缩。这种压缩实际上只是用来微妙地将人声再向前推一些。就我个人喜好和风格而言,我喜欢MV2,尤其是它的低电平滑块。虽然我不能确切分析出它的运作机制,但它对我确实有用。R-Vox非常适合中低频需要一点额外重量的人声,也能以类似方式运用。即使是像L2这样的传统限制器也可以成为很好的“收尾者”。上述所有的关键是,压缩用量要微小。一两个dB的衰减通常就会有奇效。
5. 并联的魔法
到这一步就更深了。一旦确定了声音本身的音色和动态,我们就可以使用自己的特殊配料了。以下是我对口味选择的看法:特殊酱料是制作美味三明治的关键。然而,如果里面没有酱料,你仍然还有的吃。不错。不过,如果只有酱料而没有食物本身,你就只能吃一嘴酱——没人愿意这样。少量的特殊配料就能发挥作用,为已经存在的声音增添味道。
我喜欢用并联处理作为自己的特殊配料。并联处理就是你用现有的声音做“乘法”(创建一个副本,无论是在新通道上,还是添加一个发送到专用的辅助通道上),然后处理这个新信号并将其与原始信号混合起来。
对于并联压缩,传统来说,其目标是通过快速启动和释放激发人声的活力。然后,我们根据需要给压缩的人声以足够的电平,使整体人声真正跳脱出来。我很多年都只用CLA-76 Bluey来做并联压缩,其他任何东西都没用过。
当然,有时你可能想做一些更激进的事情。创建一条“超级微笑”均衡曲线,底部和顶部都非常夸张,再通过失真插件给人声带来惊人效果。你可以试试Manny Marroquin Distortion插件——用到足够给信号“一点颜色”,再把它与主人声混合在一起——这样它就像是个很酷的激励器了。
6. 如果我的人声很糟糕怎么办?
我讲的这些都多少取决于一开始是否有良好的录音,但我们并非是那么幸运。如果声音录得很薄,该怎么办呢?好吧,我们还有选择。我喜欢创造我称之为“假谐波”的东西,它们是真正的谐波,但在原始录音中并不存在。更简单地说,我使用失真通过添加谐波能量来创建完满的印象。Manny Distortion插件就能完成这项工作,但你必须非常理智地进行设置,牵一发而动全身。调节插件直到几乎听不出失真时,再做A/B对比听听看。
另一个选择是Manny Tone Shaper,它在分段处理器中结合了饱和与压缩。即使你只是激活频段而不真正调节,源信号也会饱满一点。然后你可以通过调整推子来定位处理任何欠火候的频率范围。
最后,你还可以用Vitamin之类的插件,让中低频段尽可能变宽。虽然机制略有不同,但想法本质上是相同的:添加谐波内容来补足源信号!
小提示:在链路之首做此操作。可能会出现一些额外的音色堆积;没关系,用EQ能解决。
7. 围绕人声进行混音
该说的都说完了,你已经拥有了响亮的人声,但是还有可能再毁掉它!如果将混音中的其他元素推得太靠前,你的人声音仍然会相形见绌。到目前为止你在人声方面所做的所有工作应该可以让你开始把混音中的其他元素往前推推,但如果你做过火了,就仍然令人声沉底。尽管在原声吉他上700Hz的提升听起来很酷,但为了人声,你可能不得不将其拿掉。吉他手可能会生气,但我们必须放眼全局。不要为人声留出过多空间——这样你的混音会变薄——但也别把其他所有元素搅和到能掩盖人声的程度。
接下来,你就可以选择如何定义你的声场,做电平自动化,尽情发挥创意了。
最后,你还可以在Waves的StudioVerse链路社区中搜索人声相关的链路,快速尝试来自顶级工程师和世界各地用户设计制作的预设,帮你节省时间,或给予启发。比如,在StudioVerse里搜索本文的核心关键词——“big”和“vocal”标签,看看会有什么结果呢?

StudioVerse官网页面:
www.waves.com/sv
音乐创意无限,插件终极体验
www.waves.com

文章出处 https://mp.weixin.qq.com/s/yGmAinzqNhae_eoRTWQ-yw
转载新闻请注明出自 Midifan.com