Stable Audio 2.0 来袭,通过音频输入实现可控 AI 智能音乐生成
2023年9月发布的Stable Audio 1.0凭借其根据文本描述生成简短音频的能力而引起了人们的关注。最新发布的2.0版本允许用户以44.1 kHz采样率生成长达三分钟的立体声完整歌曲,超过了过去1.0版本90秒的限制。除了增加长度之外,Stable Audio 2.0还提供其他功能,包括新的“音频到音频”功能,允许用户上传已有的音乐或者直接哼唱来影响生成的音乐特征。
图1:更新后的Stable Audio界面
2023年9月发布的Stable Audio 1.0(新闻请参考《深入揭发音乐人的噩梦 Stable Audio:音乐生成 AI 的商业技术背景 + 使用教程》)凭借其根据文本描述生成简短音频的能力而引起了人们的关注。最新发布的2.0版本[https://stableaudio.com/user-guide/model-2]允许用户以44.1 kHz采样率生成长达三分钟的立体声完整歌曲,超过了过去1.0版本90秒的限制。除了增加长度之外,Stable Audio 2.0还提供其他功能,包括新的“音频到音频”功能,允许用户上传已有的音乐或者直接哼唱来影响生成的音乐特征。
https://www.youtube.com/watch?v=cljN977HNTI
视频中展示了Stable Audio可以将用户输入音频和提示词进行结合,并输出与两者都有关联的音乐。输入音频可以是哼唱,也可以是简单的乐器演奏。除此之外,用户还可以通过Prompt strength来调节输入音频和提示词对结果的影响权重。在展示视频中,合成器贝斯被转换为低音吉他,一段哼唱转换成鼓的音高和节奏,Beatbox变成了嘻哈beat。不过小编简单尝试了这个功能后发现生成结果与输入音频关系不太大,服务器也不太稳定。更多关于音频到音频生成的官方音频示例可访问:https://stableaudio.com/user-guide/audio-to-audio。Stable Audio 2.0还表示新版本加入了诸如风格转换之类的功能,不过在官方指南内没有找到更详细的信息,有可能指的就是音频文本提示词生成的变体。
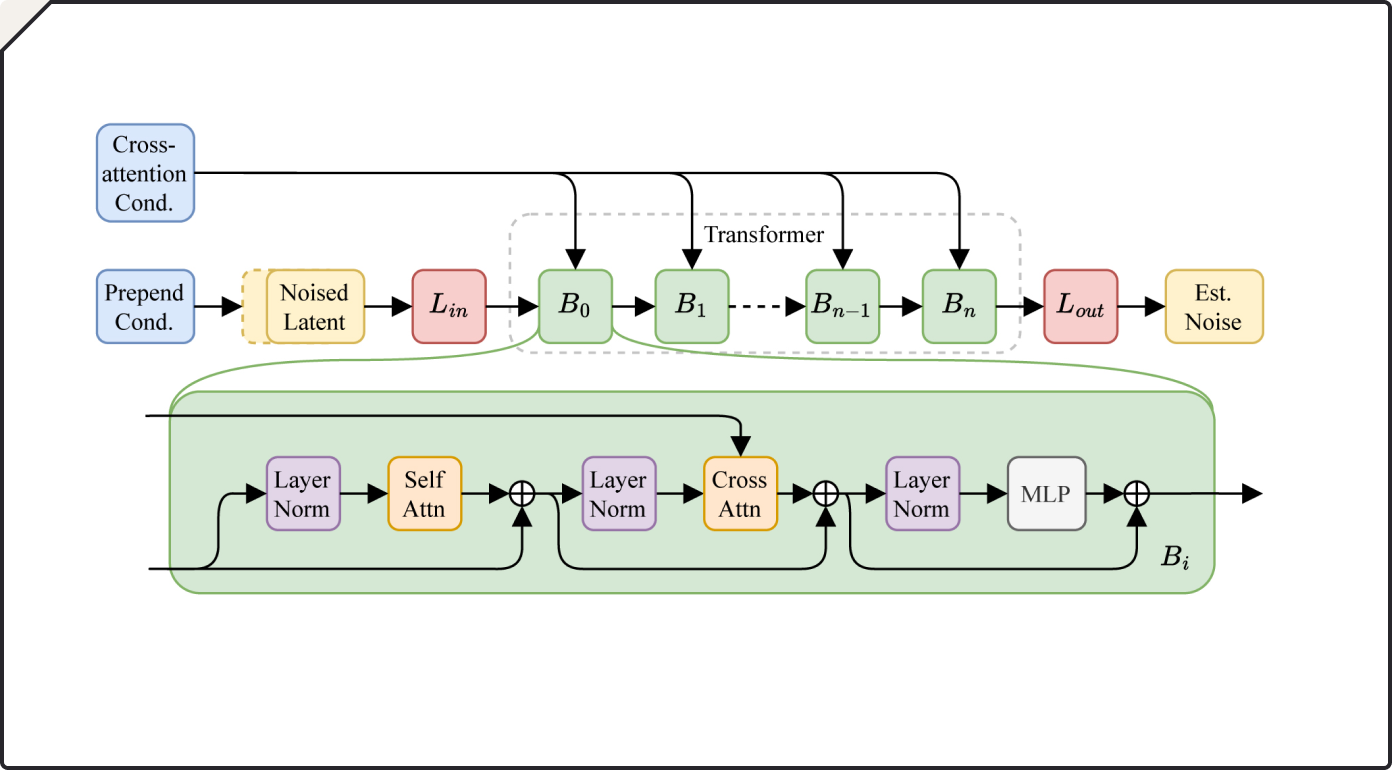
图2:Diffusion Transformer (DiT)
根据官网介绍,Stable Audio 2.0的隐含扩散(Latent Diffusion)模型架构经过专门设计,能够生成具有连贯结构的完整音轨。为了实现这一目标,团队对系统的所有组件进行了调整,以提高长时内容生成的性能。一种全新的高度压缩的自动编码器(Auto-Encoder)将原始音频波形压缩为更短的表示形式。扩散模型采用类似于Stable Diffusion 3中使用的diffusion transformer(DiT)来代替之前的U-Net,因为它更擅长处理长序列的数据。 这两个元素的结合产生了一个能够识别和再现高质量音乐作品所必需的大模型结构。
新模型可在 Stable Audio 网站上免费使用,并将很快提供Stable Audio 2.0 API。Stability AI还推出了Stable Radio[https://stableaudio.com/live],一个全天候直播Stable Audio生成曲目的YouTube推流。
Stable Audio 2.0的发布正值Stability AI内部动荡。公司劣迹斑斑的前CEO Emad Mostaque于3月23日被迫辞职。2023年11月,该公司前音频副总裁Ed Newton-Rex因在训练数据集中使用受版权保护的材料存在分歧而选择离职抗议。该起事件详情请见midifan报道番外篇“训练数据侵权,Stable Audio研发主管辞职抗议”(参考新闻《风格迁移 AI 效果器 Comboulator 发布,另有一波 Google 和 Adobe 音乐 AI 新品袭来》)。Ed Newton-Rex之后发起了一项名为Fairly Trained[https://www.fairlytrained.org/],旨在对基于尊重创作者权利的人工智能模型的评估和认证。
Stability AI如今声称解决了人工智能开发的版权问题,表示:
“Stable Audio 2.0专门在AudioSparx音乐库[https://www.audiosparx.com/]许可数据集上进行了训练,尊重选择退出训练计划的音乐家并确保创作者得到公平的补偿。”
这个说法与去年Stable Audio 1.0发布时的说辞(参考新闻《深入揭发音乐人的噩梦 Stable Audio:音乐生成 AI 的商业技术背景 + 使用教程》)如出一辙,很难不让人再对其产生怀疑。
根据过往资料,模型的训练使用了AudioSparx中超过80万段音频,其中包含音乐、音效和单乐器轨道以及相应的文本数据。Stability AI表示本次2.0版本集成了来自Audible Magic[https://www.audiblemagic.com/]的内容识别技术来扫描用户上传的音频是否侵犯版权,却并未提到有检查其训练数据的侵权情况。
虽然 Stability AI拒绝对Ed Newton-Rex的声明发表评论,但他们重申:
“Stable Audio模型仅根据AudioSparx合作伙伴的数据进行训练。AudioSparx的所有艺术家都获得了补偿,并且可以选择退出模型训练计划”。关于Stable Audio等工具的技术不断进步是否有潜力影响职业音乐家的生计,Stability AI回应称他们的使命是放大人类的潜力,其中包括艺术家。“我们的目标是利用我们的尖端技术扩展艺术家的创意工具包,从而提高他们的创造力。”
近几个月来,人工智能驱动的生成音乐工具受到批评,因为艺术家和唱片公司开始质疑它们不受控制的发展未来可能会引导我们走向何方。就在本周,包括Billie Eilish和Stevie Wonder在内的200名艺术家签署了一封公开信,要求遏制“人工智能的掠夺性使用”。
番外:Billie Eilish、Nicki Minaj、Stevie Wonder等音乐家要求保护免遭人工智能侵害
由200多名知名音乐家组成的团体签署了一封公开信,呼吁保护人们免遭模仿人类肖像和声音的人工智能掠夺性影响。签名者跨越音乐流派和时代,包括从Billie Eilish、J Balvin、Nicki Minaj这样的一线明星到Stevie Wonder和REM等摇滚名人堂成员。弗兰克·辛纳屈 (Frank Sinatra)和鲍勃·马利 (Bob Marley) 的遗产管理机构也是签署人。
这封信由艺术家权利联盟Artist Rights Alliance[https://artistrightsalliance.org]发出,要求科技公司承诺不开发破坏或取代人类歌曲作者和艺术家的人工智能工具。信中指出:
“这种对人类创造力的攻击必须停止。 我们必须防止人工智能被掠夺性地用来窃取专业艺术家的声音和肖像、侵犯创作者的权利并破坏音乐生态系统,”

图3:公开信内容截图
这封信并未呼吁彻底禁止在音乐或制作中使用人工智能,而是表示负责任地使用该技术可能会给该行业带来好处。对人工智能被用来写歌曲和剧本,或者制作演员和艺人的图像和视频的担忧,是2023年美国娱乐业工会罢工的核心。就在上周,出于对负责任使用的担忧,ChatGPT制造商OpenAI推迟了一款可以模仿声音的程序的发布。
2024年3月,田纳西州成为美国第一个颁布立法的州,旨在保护音乐家免于将人工智能生成的相似声音用于商业目的。《肖像、声音和图像安全法案》(The Ensuring Likeness, Voice, and Image Security Act,又称《猫王法案》Elvis Act)将于同年7月1日生效,规定未经艺术家同意复制其声音为违法行为。该立法并未涉及将艺术家的作品用作训练人工智能模型的数据,而这种做法已导致针对OpenAI等公司的多起诉讼,信中也提到了这一点。
信中还指出:
“一些最大、最有实力的公司未经许可,使用艺术家的工作来训练人工智能模型。其直接目的是用大量人工智能创造的‘声音’和‘图像’取代人类艺术家的作品,从而大大稀释支付给艺术家的版税。”
艺术家权利联盟是一个由音乐行业资深人士运营的非营利组织,董事会成员包括Johnny Cash的女儿Rosanne Cash。目前还不清楚该组织是如何联系到在这封信上签名的艺术家的。除前文中提到的署名者,名单还包括Camila Cabello, Katy Perry, Kim Petras, Pearl Jam, Kacey Musgraves, Ayra Starr, Chuck D, Elvis Costello, Imagine Dragons, Jon Bon Jovi, Q-Tip, The Cure’s Robert Smith, Ryan Tedder, Sheryl Crow, Sam Smith, Smokey Robinson, Miranda Lambert, The Last Dinner Part, Chappell Roany等知名艺人。完整名单请访问链接[https://artistrightsnow.medium.com/200-artists-urge-tech-platforms-stop-devaluing-music-559fb109bbac]。代表已故艺术家的遗产机构也是这封信的签署者之一。娱乐行业内关于艺术家死后如何使用他们的肖像的争论越来越多。近年来,已故演员和音乐家的多个人工智能版本出现在电影、视频游戏和电视中,引发了争议和伦理辩论。
参考链接:
转载新闻请注明出自 Midifan.com